카테고리 없음
챗봇 구현 실습을 통한 싱글턴 (Single-turn)과 멀티턴 (Multi-turn) 차이 비교 (+ 스트리밍 처리)
데이by데이
2025. 7. 9. 13:04
간단한 챗봇 구현으로 알아보는 싱글턴과 멀티턴 차이
ChatGPT와 대화를 할 때 이전의 대화 내용을 기억하고 있어 질문을 모호하게 했는데도 찰떡같이 알아듣고 잘 대답해 준 경험이 있는데요. 이렇게 이전 대화 내용을 기억하고 여러 번 대화를 주고받으면서 응답하는 방식을 멀티턴이라고 합니다. 멀티턴이 가능한 챗봇을 구현하기 위해 싱글턴과 멀티턴의 개념 차이를 다시 한번 짚고, 구현 코드와 결과를 비교해보고자 합니다. 그리고 실제 챗봇처럼 스트리밍 방식으로 응답이 빠르게 출력되는 것까지 간단하게 Gradio를 통해 구현해 보겠습니다.
Gradio
- Gradio는 머신러닝 모델을 웹 앱으로 쉽게 배포할 수 있도록 도와주는 사용자 친화적인 인터페이스를 갖춘 python 기반 오픈소스 라이브러리입니다.
- 특징
- 간단한 UI 구성 : 복잡한 프론트엔드나 서버 설정 없이도 간단하게 인터렉티브한 웹 UI를 만들 수 있습니다.
- 다양한 입력 형식 지원 : 텍스트나 이미지, 오디오, 비디오 등 다양한 입력 형식을 모델에 제공할 수 있습니다.
- 빠른 시제품 개발 : 모델 개발 후 바로 인터페이스 생성이 가능합니다.
- 웹 브라우저 실행 : 로컬 또는 공유 가능한 URL로 바로 테스트가 가능합니다.
싱글턴과 멀티턴 개념 비교
싱글턴 (Single-turn)
- 정의
- 사용자가 질문을 하거나 요청을 하면, 시스템이 응답한 후 바로 대화가 끝나는 방식입니다.
- 특징
- 대화가 단방향이며 1번의 질문에 1번의 대답만을 제공합니다.
- 상황이나 맥락을 유지하지 않기 때문에 매 입력마다 독립적으로 응답이 생성됩니다.
- 맥락 없이 응답하는 단발성 응답이기 때문에 반응속도가 빠릅니다.
- 사용 사례
- 단일 질의응답 시스템 (FAQ 등)
- 예시
- 사용자가 "날씨 어때?"라고 질문한 후 "내일은?"이라고 추가 질문을 했을 때, 시스템이 날씨에 대한 내용이 아닌 "내일"에 대한 정의를 대답하는 식.
- User: "서울 날씨 어때?"
Bot: "오늘 서울은 맑고 기온은 27도입니다.
User: "내일은?"
Bot:" 내일은 오늘 날짜에서 하루 뒤입니다. 오늘이 몇 월 며칠인지 말씀해 주시면, 내일의 날짜를 알려드릴 수 있습니다!"
멀티턴 (Multi-turn)
- 정의
- 사용자가 여러 번 질문을 하고, 그에 따라 시스템이 지속적으로 반응하는 대화 방식으로 대화가 여러 번의 턴으로 이루어집니다.
- 특징
- history를 기반으로 이전 대화 맥락을 포함하여 추가 질문이나 요청을 할 수 있습니다.
- 이전 대화 내용을 모두 기억하여 응답하기 때문에 반응 속도가 느릴 수 있습니다.
- 사용 사례
- 컨텍스트 유지가 중요한 질의응답, 상담 챗봇
- 예시
- 사용자가 "날씨 어때?"라고 질문한 후 "내일은?"이라고 추가 질문을 했을 때, 시스템이 "내일은 비가 올 거예요."라고 대답하는 식.
- User: "서울 날씨 어때?"
Bot: "오늘 서울은 맑아요."
User: "내일은?"
Bot: "내일은 흐리고 비가 올 예정이에요."
싱글턴과 멀티턴 구현 결과 비교
싱글턴 구현
!pip install -U gradioimport os
import json
from openai import OpenAI
os.environ["OPENAI_API_KEY"] = "your key" # 실제 키로 대체
client = OpenAI()
client.api_key = os.getenv("OPENAI_API_KEY")import gradio as gr
def chat(history, input):
messages = [{"role": "user", "content": input}]
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
)
response_message = response.choices[0].message
return history + [(input, response_message.content)]
with gr.Blocks() as demo:
chatbot = gr.Chatbot()
textbox = gr.Textbox()
textbox.submit(chat, [chatbot, textbox], [chatbot])
demo.launch(server_name='0.0.0.0')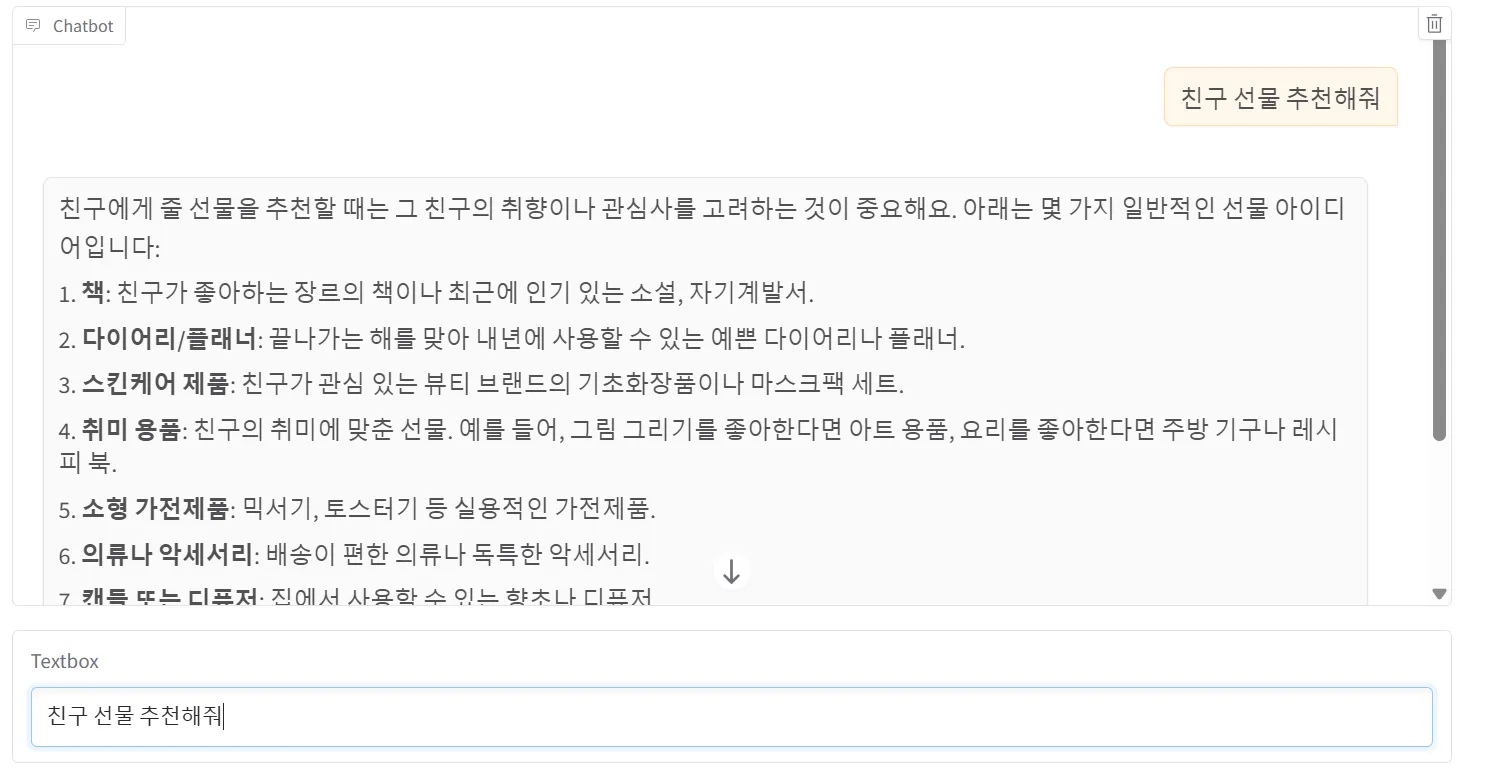
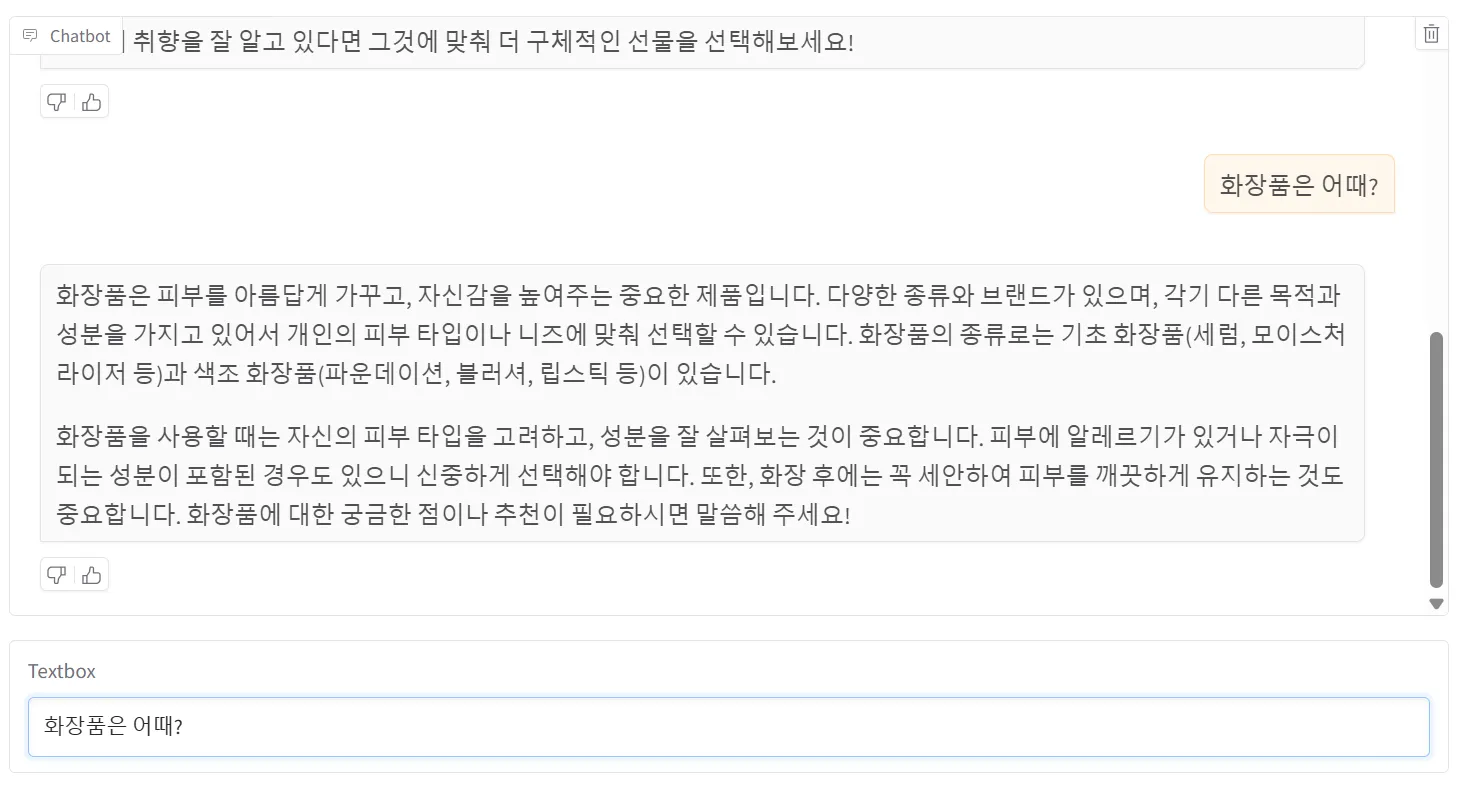
멀티턴 구현
import gradio as gr
def chat(history, input):
"""
ChatGPT와 대화하는 함수
Args:
history: 이전 대화 기록 (리스트 형태)
input: 사용자가 입력한 메시지
Returns:
업데이트된 대화 기록
"""
# OpenAI API에 전송할 메시지 리스트 초기화
messages = []
# 히스토리를 통해 모델에 모든 이전 대화 내용을 포함시킴
# 멀티턴 대화를 위해 이전 대화 내용을 컨텍스트로 제공
for user_input, bot_output in history:
messages.append({"role": "user", "content": user_input})
messages.append({"role": "assistant", "content": bot_output})
# 마지막에 현재 사용자 입력 추가
messages.append({"role": "user", "content": input})
# OpenAI API 호출하여 ChatGPT 응답 생성
response = client.chat.completions.create(
model="gpt-4o-mini", # 사용할 모델 지정
messages=messages, # 대화 히스토리 포함된 메시지 전송
)
# API 응답에서 실제 메시지 내용 추출
response_message = response.choices[0].message
# 새로운 대화 내용을 히스토리에 추가하여 반환
return history + [(input, response_message.content)]
# Gradio 웹 인터페이스 구성
with gr.Blocks() as demo:
# 채팅 인터페이스 컴포넌트 생성
chatbot = gr.Chatbot() # 대화 내용을 표시할 채팅창
textbox = gr.Textbox() # 사용자 입력을 받을 텍스트 박스
# 텍스트 박스에서 엔터키를 누르면 chat 함수 실행
# 입력: chatbot(대화 히스토리), textbox(사용자 입력)
# 출력: chatbot(업데이트된 대화 히스토리)
textbox.submit(chat, [chatbot, textbox], [chatbot])
demo.launch(server_name='0.0.0.0')

멀티턴 + 스트리밍 처리 추가
위의 처리 방식은 챗봇의 응답을 모두 생성한 후 응답을 출력하는 방식이기 때문에 사용자의 대기 시간이 길다는 단점이 있습니다. 이를 보완하기 위해 사용자가 응답을 바로 실시간으로 확인할 수 있도록 응답이 생성하는 순간 바로 출력하도록 스트리밍 처리를 해줄 수 있습니다.
def chat_stream(history, input):
"""
ChatGPT와 스트리밍 방식으로 대화하는 함수
Args:
history: 이전 대화 기록 (리스트 형태)
input: 사용자가 입력한 메시지
Yields:
업데이트된 대화 기록 (스트리밍 방식)
"""
# OpenAI API에 전송할 메시지 리스트 초기화
messages = [{"role": "user", "content": input}]
# 히스토리를 통해 모델에 모든 이전 대화 내용을 포함시킴
# 멀티턴 대화를 위해 이전 대화 내용을 컨텍스트로 제공
for user_input, bot_output in history:
messages.append({"role": "user", "content": user_input})
messages.append({"role": "assistant", "content": bot_output})
# OpenAI API 호출하여 ChatGPT 응답을 스트리밍 방식으로 생성
stream = client.chat.completions.create(
model="gpt-4o-mini", # 사용할 모델 지정
messages=messages, # 대화 히스토리 포함된 메시지 전송
stream=True, # 스트리밍 모드 활성화
)
# 스트리밍 응답을 실시간으로 처리
partial_message = ""
for chunk in stream:
if chunk.choices[0].delta.content is not None:
partial_message += chunk.choices[0].delta.content
# 실시간으로 업데이트된 대화 기록을 yield
yield history + [(input, partial_message)]
# Gradio 웹 인터페이스 구성
with gr.Blocks() as demo:
# 채팅 인터페이스 컴포넌트 생성
chatbot = gr.Chatbot() # 대화 내용을 표시할 채팅창
textbox = gr.Textbox() # 사용자 입력을 받을 텍스트 박스
# 텍스트 박스에서 엔터키를 누르면 chat_stream 함수 실행
# 입력: chatbot(대화 히스토리), textbox(사용자 입력)
# 출력: chatbot(업데이트된 대화 히스토리) - 스트리밍 방식
textbox.submit(chat_stream, [chatbot, textbox], [chatbot])
# 웹 서버 실행 (모든 네트워크 인터페이스에서 접근 가능)
demo.launch(server_name='0.0.0.0')